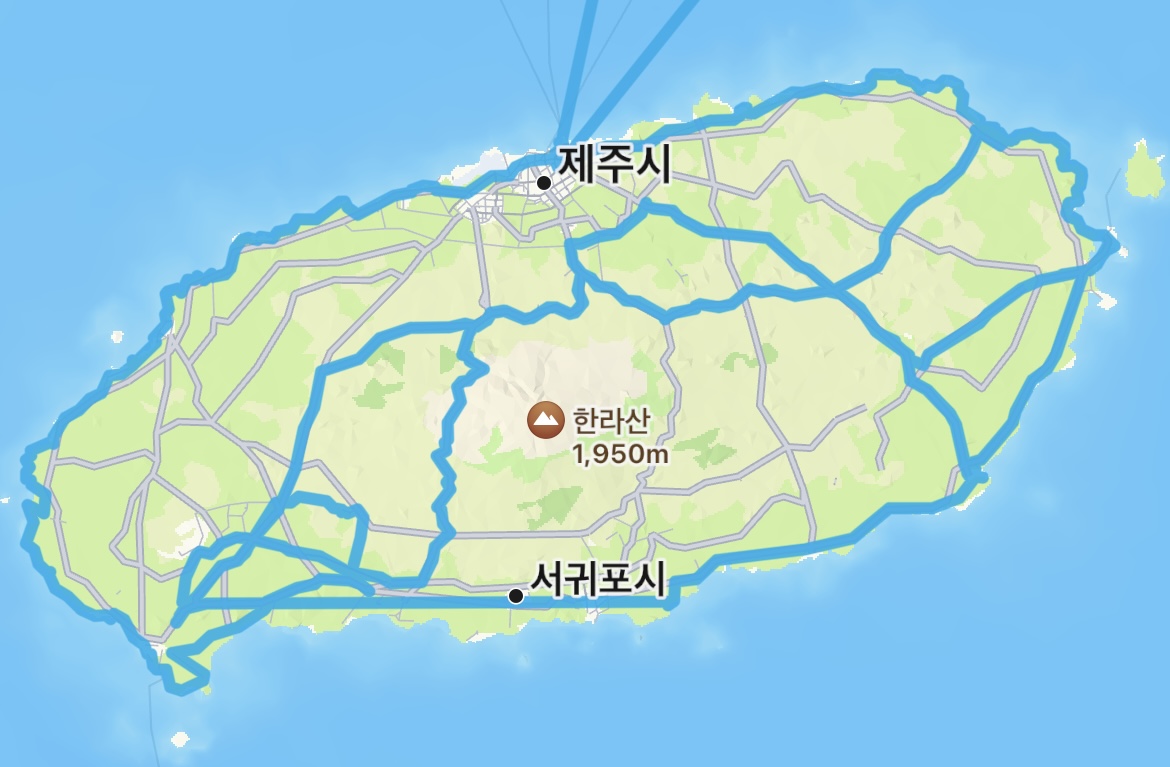
작년 가을에 가려고 했으나 못갔던 제주도 투어를 다음주에 가려고 한다.
제주내에서 2박 3일, 항구까지 2일 해서 4박 5일 정도의 일정을 생각중이다.
바이크를 어떻게 가져갈지 고민했는데 목포항에서 배타고 들어가기로 했다.
- 탁송을 보낼지
- 배를 탈지
- 완도에서 탈지
- 2시간 30분으로 배 소요시간이 가장 짧다.
- 02:30 / 05:10, 15:00 / 17:40
- 목포에서 탈지
- 5시간 소요
- 01:00 / 06:00, 08:45 / 13:15
- 여수
완도 배 시간은 좀 애매하다. 목포에서 1시 배를 타고 가는동안 잠을 자고 도착해서 바로 투어를 시작하는게 좋을것 같다.
하지만 월요일에는 1시 출발하는 배가 없다. 여수를 살펴보니 00:20 출발하는 배가 있어서 결국 여수에서 출발하기로 함
인천에서 출발하는 배가 있으면 좋겠는데 무슨일인지 없다.
집에서 목포항까지 6시간 13분 432KM 거리이다.
중간에 쉬고 밥먹고 차를 23시쯤 선적한다고 해도 시간이 충분하다.
432km 는 한번에 가는 최장거리가 될것 같다.
여수 엑스포 여객선터미널까지 집에서 407KM
중간에 쉬고 밥먹고 차를 22시쯤 선적한다고 해도 시간이 충분하다. 체력이 따라줄지가 문제다.
407km 는 한번에 가는 최장거리가 될것 같다.
제주도에서는
첫째날 제주 한바퀴를 돌아볼까 생각중
둘째날 1100고지, 사려니숲길 등 내륙에서 갈만한 곳들을 투어하고
셋째날 육지로 돌아가기
제주도 맛집
- 고기덕후
- 은희네해장국
- 명진전복
- 평대스낵
- 벵디
- 금능낙원(새벽오픈)
- 삼무국수
- 우진해장국
-
카페
- 친봉상장
- 동광
- 델문도
- 보롬왓
- 몽상드애월
- 서연의집(건축학개론)
- 휘닉스
- 카페루시아
갈곳
- 신창 풍차해안도로
- 516도로
- 비자림로
- 월정리 해안도로
- 1100 고지
- 방주교회
- 산방산
- 녹산로유채꽃도로
제주도에서 돌아올때는 완도로 갈지 목포로갈지 좀 고민된다.
완도행 : 07:20 / 10:00, 19:30 / 22:10
목포행 : 13:40 / 18:10, 16:45 / 21:15
아침 일찍 완도로 와서 좀 천천히 올라가면서 둘러보고 여유롭게 집으로 갈지
제주도에서 최대한 늦게까지 있다가 19:30 배를 타고 완도로 와서 일박하고 다음날 집으로 빡시게 이동할지
목포로 와서 일박하고 다음날 집으로 다시 빡시게 올라갈지
고민된다.
완도로 일찍와서 올라가는 길 중간에 일박하고 가는것으로 정했다.